

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
pythonではデータ解析をよく行います。
そんな中よく使うデータといえば、表データではないでしょうか?
表データは次のようなデータです。
エクセルのデータだったり、データベースのデータのことです。
| 列名 | 列名 | 列名 |
この表データを簡単に扱うことができるのが、pandasというライブラリです。
今回はpandasについて習得していきます。
本記事のサンプルコード
>>サンプルコード(jupyter notebook)

目次
pandasについて
pandasはデータ解析やデータ操作、計算などを簡単にするライブラリです。
主に、表データを取り扱います。
インストール
インストールは下記のように、pipで行います。
|
1 |
pip install pandas |
読み込み
ライブラリの読み込みは、次のようにします。
|
1 |
import pandas as pd |
DataFrameについて
pandasで取り扱う、データはDataFrameという型で取り扱います。
DataFrameは次のような「values」「columns」「index」で構成されます。

pandasの基本 データを取り出して計算する
まず、基本的な使い方を抑えていきましょう。
DataFrameを作って、データを取り出し、計算するところまでを紹介します。
データを作る
簡単なDataFrameを作っていきます。
valuesのみを指定すると自動でcolumnsとindexがつく
listで2次元データを作って、valuesのみを与えたDataFrameを作ってみます。
df = pd.DataFrame(listデータ)
|
1 2 3 4 5 |
list_a = [[1, 2, 3], [4, 5, 6], [7, 8, 9],] df = pd.DataFrame(list_a) print(df) |
|
1 2 3 4 |
0 1 2 0 1 2 3 1 4 5 6 2 7 8 9 |
listでvaluesのみのデータを作ったはずが、columnsとindexがあります。
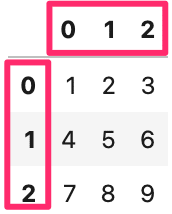
ない場合は、勝手に0, 1, 2,…と割り当てられます。
columns名,index名を指定する
valuesと一緒に、colums、indexもつけてみましょう。
*行名、列名はlist、tupleなどの配列で与える
|
1 2 3 4 5 6 7 |
list_a = [[1, 2, 3], [4, 5, 6], [7, 8, 9],] col_name = ['col1', 'col2', 'col3'] ind_name = ['ind1', 'ind2', 'ind3'] df = pd.DataFrame(list_a, columns=col_name, index=ind_name) print(df) |
|
1 2 3 4 |
col1 col2 col3 ind1 1 2 3 ind2 4 5 6 ind3 7 8 9 |
行列名がつきました。
大抵は、列名だけをつけることが多いです。その場合、indexを省略すればOKです。
エクセルにしても、データベースにしても列名のみが多いためです。
indexは0,1,2,..の連番で十分というのもあります。
CSVの読み込み、データの確認
CSVの読み込みやデータの確認は、下記の以前の記事を参照ください。
下記、添付の加工帳明細のデータを読み込みます。
次のコードで読み込みます。
|
1 2 |
df = pd.read_csv('加工帳明細.csv', encoding='cp932', header=2) df.head() |
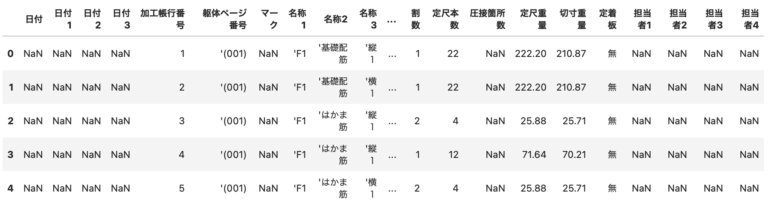
読み込んだdfは、この記事でこれからで使っていきます。
データを取り出す
読み込んだデータを取り出す方法について紹介します。
まず、 DataFrameを構成するものを取り出します。
index, columns, valuesを取り出す
|
1 2 3 |
print(df.index) print(df.columns) print(df.values) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
RangeIndex(start=0, stop=7, step=1) Index(['日付', '日付1', '日付2', '日付3', '加工帳行番号', '躯体ページ番号', 'マーク', '名称1', '名称2', '名称3', '形状番号', '径', '材質', '切寸法', '切寸本数', '箇所数', '切寸合計本数', '定尺長さ', '割数', '定尺本数', '圧接箇所数', '定尺重量', '切寸重量', '定着板', '担当者1', '担当者2', '担当者3', '担当者4'], dtype='object') [[nan nan nan nan 1 "'(001)" nan "'F1" "'基礎配筋" "'縦1" nan 'D19' 'SD345' 4260 22 1 22 4500 1 22 nan 222.2 210.87 '無' nan nan nan nan] [nan nan nan nan 2 "'(001)" nan "'F1" "'基礎配筋" "'横1" nan 'D19' 'SD345' 4260 22 1 22 4500 1 22 nan 222.2 210.87 '無' nan nan nan nan] [nan nan nan nan 3 "'(001)" nan "'F1" "'はかま筋" "'縦1" nan 'D13' 'SD295A' 3230 8 1 8 6500 2 4 nan 25.88 25.71 '無' nan nan nan nan] [nan nan nan nan 4 "'(001)" nan "'F1" "'はかま筋" "'縦1" nan 'D13' 'SD295A' 5880 12 1 12 6000 1 12 nan 71.64 70.21 '無' nan nan nan nan] [nan nan nan nan 5 "'(001)" nan "'F1" "'はかま筋" "'横1" nan 'D13' 'SD295A' 3230 8 1 8 6500 2 4 nan 25.88 25.71 '無' nan nan nan nan] [nan nan nan nan 6 "'(001)" nan "'F1" "'はかま筋" "'横1" nan 'D13' 'SD295A' 5880 12 1 12 6000 1 12 nan 71.64 70.21 '無' nan nan nan nan] [nan nan nan nan 7 "'(001)" nan "'F1" "'腹筋" "'横1" nan 'D13' 'SD295A' 4730 4 1 4 5000 1 4 nan 19.92 18.83 '無' nan nan nan nan]] |
上から、index,columns,valuesが表示されています。
列名を確認するときに使うことが多いです。
列単位で取り出す
この列とこの列が欲しいと言ったように列単位で取り出す場合は、列名をlistで渡します。
df[列名の配列]
このでは、先ほど確認した列名の結果を見ると、次の列名があります。
|
1 2 3 |
['日付', '日付1', '日付2', '日付3', '加工帳行番号', '躯体ページ番号', 'マーク', '名称1', '名称2', '名称3', '形状番号', '径', '材質', '切寸法', '切寸本数', '箇所数', '切寸合計本数', '定尺長さ', '割数', '定尺本数', '圧接箇所数', '定尺重量', '切寸重量', '定着板', '担当者1', '担当者2', '担当者3', '担当者4'] |
なので、ここから、取得した列名を指定するだけです。
例えば、「径」「材質」であれば、次のようになります。
|
1 |
df['径', '材質'] |

不要な列を削って、必要な列のみのデータにするときに使います。
行単位で取り出す
行単位で取り出す場合は、取得する行数を指定します。
df[開始行数:終了行数]
*行数は0から始まり、終了行数の1つ前まで取得します。
例えば、2行目目から4行目目まで取得する場合は次のようにします。
|
1 |
df[1:4] |

座標指定で取り出すiloc,loc
図のように、部分的にデータを取り出したい場合は、iloc若しくはlocを使います。
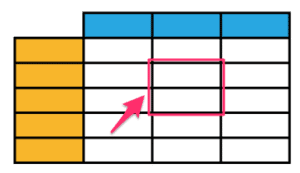
ilocでは数値で座標を指定します。
df.iloc[開始行数:終了行数,開始列数:終了列数]
*行数は0から始まり、終了行数の1つ前まで取得します。
2行目-4行目、4列目-6列目まで取得してみます。
|
1 |
df.iloc[1:4, 3:6] |
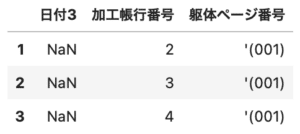
開始行数:終了行数,開始列数:終了列数はそれぞれ、省略することが可能です。
省略時は、開始行列数の場合は0から、終了行列数は最終までが指定されます。
例えば、下記表のように色々な使い方があります。
| df.iloc[:,3:6] | 全行、4列目-6列目 |
| df.iloc[1:4, :] | 2行目-4行目、全列 |
| df.iloc[2:, 3:6] | 3行目-最終行、4列目-6列目 |
| df.iloc[1:4, :6] | 2行目-4行目、開始列-6列目 |
locでは、行名、列名を指定します。
df.loc[行名配列, 列名配列]
1,3行目の「径」「材質」の列を取得してみます。
|
1 |
df.loc[[0, 2], ['径', '材質']] |

繰り返し処理で取り出す
行や列を順番に繰り返して、データを取り出したいということがあります。
主に、行を順番に繰り返すことが多いです。
まず、行を繰り返して取得する場合を紹介します。
行を繰り返す場合、iterrows()を使います。
for ind, row in df.iterrows():
indには行番号、rowには1行分のデータが入っていて、列名を指定するとデータが取得できます。
実際のコードでみてみましょう。
|
1 2 3 |
# 行を繰り返す for ind, row in df.iterrows(): print(ind, row[['径', '材質']]) |

次に、列を繰り返して取得する場合を紹介します。
列を繰り返す場合、iteritems()を使います。
for col_name, col in df.iteritems():
col_nameには列名、colには1列分のデータが入っていて、行数を指定するとデータが取得できます。
実際のコードでみていきましょう。
今回はcol[[0, 1]]とせず、col[0]、col[1]と1つずつ指定することもできます。
|
1 2 |
for col_name, col in df.iteritems(): print(col_name, col[0], col[1]) |

以上が、データの取り出し方です。
これらの方法で読み込んだデータを取り出せるようになっておきましょう。
計算
次はデータの計算を紹介します。
わかりやすくするため、列を[‘定尺本数’, ‘定尺長さ’]に絞ってみていきます。
統計量を確認
各列の統計量はdescribeを使うことで確認することができます。
|
1 2 |
df2 = df[['定尺本数', '定尺長さ']] df2.describe() |
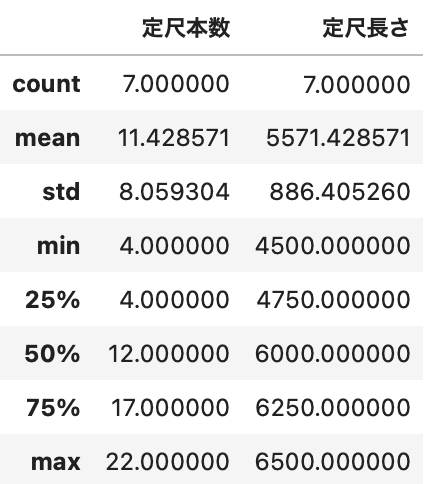
それぞれの統計量を取得したい場合は、1列目に表示されているメソッドを使うことで取得できます。
|
1 2 3 4 5 |
print('max:', df['定尺本数'].max()) print('min:', df['定尺本数'].min()) print('std:', df['定尺本数'].std()) print('mean:', df['定尺本数'].mean()) print('count:', df['定尺本数'].count()) |
|
1 2 3 4 5 |
max: 22 min: 4 std: 8.059303999253345 mean: 11.428571428571429 count: 7 |
列同士の計算
この列とこの列を計算して、新しい列を追加したい場合があります。
その時は、下記のように列同士を四則演算子で計算すると全部の行を計算してくれます。
df.[新しい列名] = df.[列名1] * df.[列名2]
|
1 2 3 4 |
df['定尺本数_長さ'] = df['定尺本数'] * df['定尺長さ'] # 計算結果も表示 df[['定尺本数_長さ', '定尺本数', '定尺長さ']].head() |

単純に値を入れても、列の数分だけ値が入ります。
|
1 2 3 4 5 |
# 1つの数字を入れる df['定尺本数_長さ'] = 0 # 計算結果も表示 df[['定尺本数_長さ', '定尺本数', '定尺長さ']].head() |
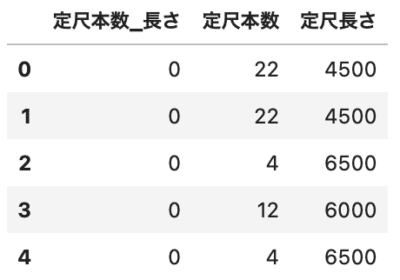
ここまでを抑えておけば、基本的なデータの読み込み、取り出し、計算ができます。
実際には、データに欠損が多かったり、より複雑な条件で取り出したいなどが出てきます。
そんな場合は、次の応用編の知識が必要となります。
pandasの応用 条件付き検索、データの欠損値の処理
ここからは、条件での検索や、データの欠損値の処理などを紹介します。
色々あるので、ざっとみて、使いたい時に見直していただくと良いです。
unipueメソッドで一意の値を取得する
データには長さや重さのような数値のものと、名称や記号のデータがあります。
名称や記号のデータをカテゴリカルデータと言います。
今使っている加工帳明細では、例えば「径」の列です。
|
1 |
df['径'] |

今はデータが少ないので、「D19」「D13」があることがわかります。
しかし、データが多い場合、全部のデータを見て確認するのは大変です。
その時は、uniqueを使い、重複のない(一意)のデータを取り出します。
|
1 |
print(df['径'].unique()) |
|
1 |
['D19' 'D13'] |
条件付き検索
データを取り出すのは基本編で紹介しました。
しかし、検索して効率的にデータを取り出したい場合があります。
検索でデータを取り出すにはいくつか方法がありますので、紹介していきます。
列ごとに条件をつける
各列ごとに比較演算子で条件を指定することで、一致する条件のデータだけ取得できます。
df2 = df[df[列名1] 比較演算子 値]
複数条件 and
df2 = df[(df[列名1] 比較演算子 値) & (df[列名2] 比較演算子 値)]
複数条件 or
df2 = df[(df[列名1] 比較演算子 値) | (df[列名2] 比較演算子 値)]
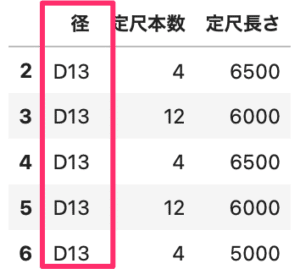
「径」列がD13のものを取得してみます。
条件指定したデータはdf2に新しく入れています。
|
1 2 3 4 5 |
# 列に条件をつける df2 = df[df['径']=='D13'] # ['径', '定尺本数', '定尺長さ']のみ表示 df2[['径', '定尺本数', '定尺長さ']] |
3列だけ表示していますが、D13のみのデータが取得できています。
これは、分解してみるとわかりやすいのですが、条件式からは一致した行がTrue/Falseが取得できます。
|
1 |
df['径']=='D13' |
|
1 2 3 4 5 6 7 |
0 False 1 False 2 True 3 True 4 True 5 True 6 True |
このTrueの箇所の行を取得しています。
locメソッドを使う
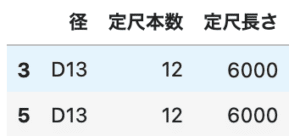
locでも同様に条件からデータを取得できます。
locをつけて、検索します。今回は、「定数本数」の条件も増やします。
|
1 2 3 4 5 |
# locを使う df2 = df.loc[(df['径']=='D13') & (df['定尺本数']==12)] # ['径', '定尺本数', '定尺長さ']のみ表示 df2[['径', '定尺本数', '定尺長さ']] |
queryメソッドを使う
queryメソッドを使った検索方法を紹介します。
queryは次のような使い方をします。
df2 = df.quey[条件式]
条件式は次のようにいくつかあります。
| 条件式 | 例 | 意味 |
| 列名 比較演算子 値 | 径 == ‘D13’ 定尺長さ > 5 |
径がD13のもの 定尺長さが5より大きい |
| not 列名 比較演算子 値 |
not 径 == ‘D13’ | 径がD13の以外のもの |
| 値 比較演算子 列名 比較演算子 値 | 5 < 定尺長さ <20 | 定尺長さが5より大きく、20未満 |
| 列名 in [‘値’, ‘値’] | 径 in [‘D13’, ‘D19’] | 径がD13、D19のもの |
| 列名 not in [‘値’, ‘値’] | 径 not in [‘D13’, ‘D19’] | 径がD13、D19以外のもの |
2つ実際に見ていきます。
|
1 2 3 |
df2 = df.query('定尺本数==4') df2[['径', '定尺本数', '定尺長さ']] |
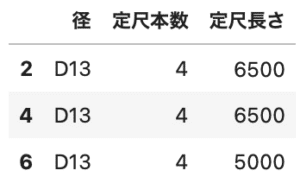
|
1 2 3 |
df2 = df.query('径 in ["D13"]') df2[['径', '定尺本数', '定尺長さ']] |
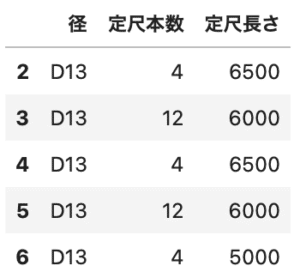
queryには文字列で条件を渡すので、シングルコーテーションで囲ったら、中の検索文字はダブルコーテーションで囲いましょう。
逆でも良いです。
他にも色々試してみてください。
関数の適用
ある列を関数を使った処理をすることが可能です。
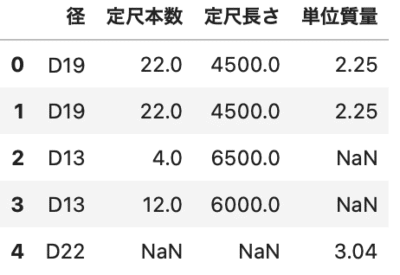
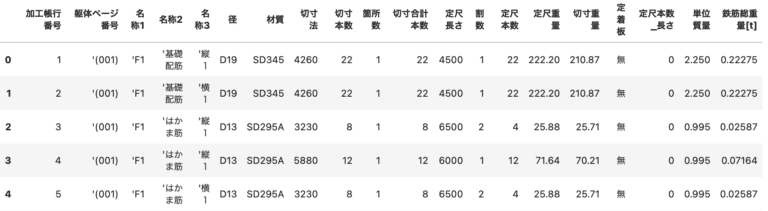
例えば、「径」列を次の表のように「単位質量」に変換したい場合があります。

その時は、mapを使います。
「径」を表から数値にした「単位質量」列を作成します。
まず、関数を用意します。
|
1 2 3 4 5 6 7 |
def func_kei(x): ret = 0 if x=='D13': ret = 0.995 if x=='D19': ret = 2.250 return ret |
引数のxには、列の値が入ってきます。
あとは、map(関数)とします。
|
1 2 |
df['単位質量'] = df['径'].map(func_kei) df[['径', '単位質量']] |
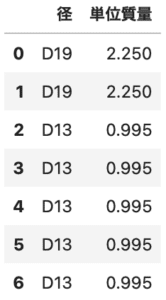
表の通りに変換できてますね。
単位質量がわかると、次のように鉄筋総重量が計算できますね。
|
1 2 3 |
# 鉄筋総重量の計算 df['鉄筋総重量[t]'] = df['単位質量'] * df['定尺長さ'] * df['定尺本数'] / 1e6 df[['鉄筋総重量[t]', '単位質量', '定尺長さ', '定尺本数']] |

結合
データは複数のリソースから取得することがあります。
例えば、ファイルが分かれている場合ですね。
結合は横方向と縦方向の結合があります。
結合では、結合となるキー列を使って、同じ値のものを結合します。
そのため、横結合はいくつか種類があります。
| 結合種類 | イメージ | メソッド | |
| 縦結合 |  |
append | |
| 横結合 | 内部 | 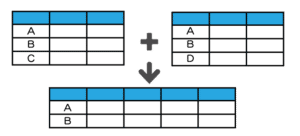 |
merge |
| 左外部 | 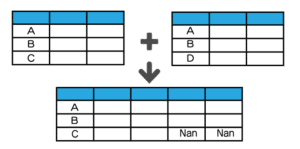 |
merge(how=”left”) *howは引数 |
|
| 右外部 | 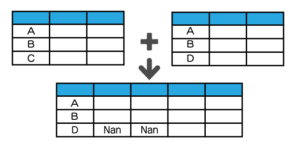 |
merge(how=”right”) *howは引数 |
|
| 外部 | 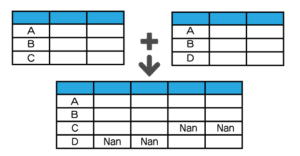 |
merge(how=”outer”) *howは引数 |
|
Nanとなっている部分は、データがないということを意味します。
結合する条件が一致しない場合は、データがないのでNanとなります。
縦結合 appendメソッド
縦結合にはappendを使います。
径をD13とD19で分けたものを、結合してみます。
df1とdf2に分けて、二つのデータを読み込んできたと仮定します。
|
1 2 3 |
# データを2つ作る df1 = df[df['径']=='D13'][['径', '定尺本数', '定尺長さ']] df2 = df[df['径']=='D19'][['径', '定尺本数', '定尺長さ']] |
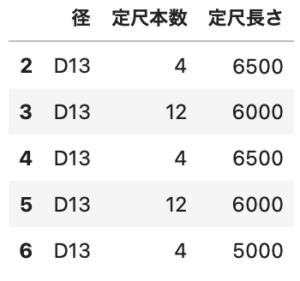
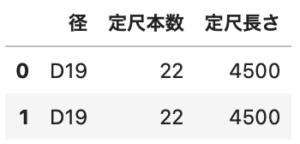
この2つを結合してdf3に入れます。
|
1 2 3 |
# 結合 df3 = df1.append(df2) df3 |
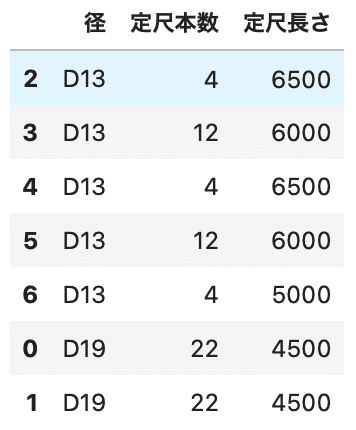
結合できていますね。
内部結合 mergeメソッド
横結合にはmergeを使います。
同じく、データを2つに分けます。
二つのデータを読み込んできたと仮定します。
|
1 2 3 |
# データを2つ作る df1 = df.iloc[:4][['径', '定尺本数', '定尺長さ']] df2 = pd.DataFrame(data=[['D19', 2.25], ['D22', 3.04]], columns=['径', '単位質量']) |
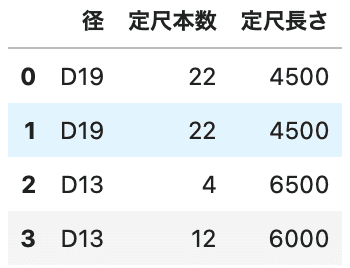
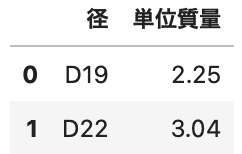
順番に見ていきます。
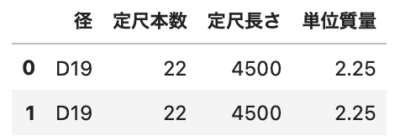
内部結合
|
1 2 3 |
# 内部結合 df3 = df1.merge(df2) df3 |
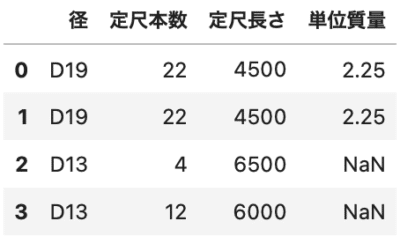
左外部結合
|
1 2 3 |
# 左外部結合 df3 = df1.merge(df2, how="left") df3 |
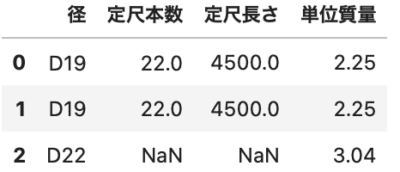
右外部結合
|
1 2 3 |
# 右外部結合 df3 = df1.merge(df2, how="right") df3 |
完全外部結合
|
1 2 3 |
# 完全結合 df3 = df1.merge(df2, how="outer") df3 |
並び替え sort_valuesメソッド
データを並べ替える場合には、sort_valuesを使います。
df2 = df.sort_values(列名, ascending=True /False)
*ascendingは省略時はTrueでTrueは昇順、Falseは降順
「関数の適用」のパートで計算した鉄筋総重量[t]を並べ替えてみます。
|
1 2 |
df2 = df.sort_values('鉄筋総重量[t]') df2[['鉄筋総重量[t]', '単位質量', '定尺長さ', '定尺本数']] |

欠損値がある場合の処理 消去/値を埋める
データはきれいに埋まってなく、データがない状態(欠損値)がある場合もあります。
欠損値の確認
欠損値であるかどうかは、isnullを使うことで確認できます。
|
1 |
df.isnull() |
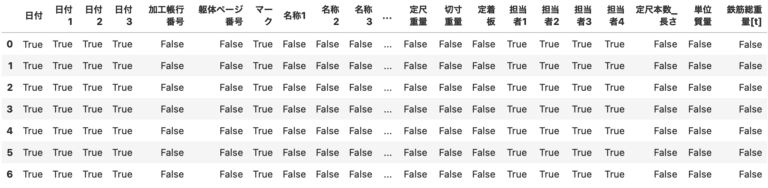
このようにTrue/Falseで判定されます。Trueが欠損値です。
True=1、False=0と扱われるので、これをsumを使って合計すると、各列の欠損値の数がわかります。
|
1 |
df.isnull().sum() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
日付 7 日付1 7 日付2 7 日付3 7 加工帳行番号 0 躯体ページ番号 0 マーク 7 名称1 0 名称2 0 名称3 0 形状番号 7 径 0 .... |
この欠損値をどうするかは、削除するか、違う値で埋めるかです。
欠損値を削除 dropnaメソッド
削除にはdropnaを使います。
df2 = df.dropna(how=”all”/”any”, axis=0/1)
*howは省略時はanyで、anyは1つでも欠損値があれば削除、allは全てが欠損値なら削除
*axisは省略時は0で、0は行方向に削除、1は列方向に削除
dropnaを引数なしで、使ってみます。
how=”any”, axis=0の状態です。欠損値がある、行を削除します。。
|
1 2 3 |
# 欠損値削除 df2 = df.dropna() df2 |
全てのデータが消えます。
次に axis=1にして、欠損値がある列を削除します。
|
1 2 3 |
# 欠損値削除 df2 = df.dropna(axis=1) df2 |
データのない列を消すことができます。
欠損値を埋める fillnaメソッド
欠損値を埋める場合は、fillnaを使います。
0で埋めてみます。
|
1 2 3 |
# 欠損値を埋める df2 = df.fillna(0) df2 |

0で埋まりましが、これ自体は何も意味をなしていません。
実際には、貴重なデータをなるべく減らさず機械学習で使いたいというときに、他のデータから判断して、平均値などで埋めます。
同じ値を持つデータを集約する groupbyメソッド
同じ値を持つデータをまとめて、平均、最大値などを計算することができます。
集約にはgroupbyを使います。
合計
df2 = df.groupby(‘列名’).sum()
平均
df2 = df.groupby(‘列名’).mean()
標準偏差
df2 = df.groupby(‘列名’).std()
中央値
df2 = df.groupby(‘列名’).median()
[‘径’, ‘定尺本数’, ‘定尺長さ’]を使って、「径」で集約してみます。
|
1 2 3 4 |
# 集約 df1 = df[['径', '定尺本数', '定尺長さ']] df2 = df1.groupby('径').mean() df2 |

この計算自体はあまり意味がありませんが、性別によるデータの平均値など計算するときに便利です。
まとめ
この記事では、データを取り出して計算するpandasの基本操作と、条件付きでデータを検索する方法やデータの欠損値を処理する方法等のpandasの応用的な操作を紹介しました。
多くのメソッドが登場し、初学者には少し難しいかもしれませんが、少しずつ習得していきましょう。