

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
狂人のごとく特定の分野、中小企業を理解し、国の補助金を獲得します。最近は中小企業のM&Aにも挑戦中
機械学習を学んでいると必ず出会うDeepLearning。
今回は実際に使ってみて、そのパワーを身を持って体験していきたいと思います。
今回は、DeepLearningを使うだけで、簡単な説明のみをして進めていきます。

目次
Deep Learningについて
DeepLearningを使う前に簡単に、DeepLearningについて知っておきましょう。
DeepLearningで学習済みモデルを使ってみよう
DeepLeaningを使うには、いくつか方法がありますが、難易度がそれぞれ違います。
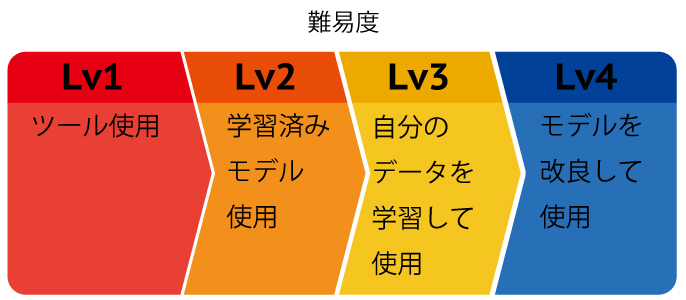
一番簡単なのは、何かしらAIツールを使うことです。
すぐ使えるのは、IBM Cloud、AWS、Azure、GCPなどのクラウドサービスは即時使えるので、試してみたい方には良いでしょう。
今回は、Lv2の学習済みモデルを使います。
これは、何万枚のデータですでに学習してあるものです。
Lv3になると、自分の持っているデータを学習させて、オリジナルAIを作って使う方法です。
学習方法を知っておく必要があるので、難易度が上がります。
Lv4はさらに、AIモデルの構造を理解して、改良することでオリジナルのAIモデルを作って活用する方法です。
ニューラルネットワークでロジスティック回帰を繰り返す
Deep Learningの前にニューラルネットワークの概要を見ていきましょう。
ニューラルネットワークはg(wx+b)のロジスティック回帰を何回か繰り返しているようなものです。
g()はシグモイド関数などの活性化関数を指しています。
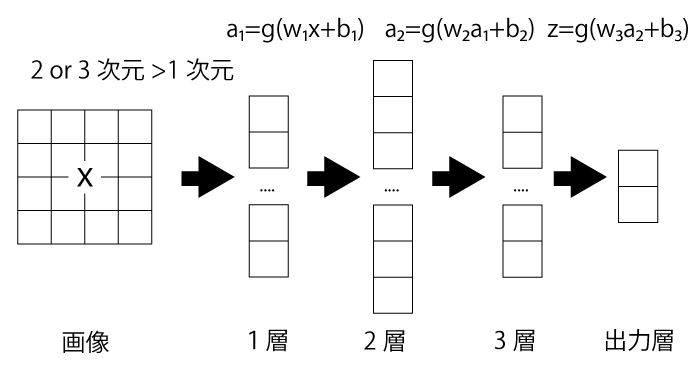
画像は、2次元若しくは3次元で表せるので、1次元に直して、何回かwx+b & シグモイド関数(活性化関数)を繰り返します。
これでもある程度の精度が出ます。
実際には、w、a、b、xなどは配列ですが、やっていることは掛け算と足し算を繰り返しているようなものなので、大体の処理イメージをつかんでもらえれば良いかと思います。
画像などのデータを欲しいデータの形や結果に変換
DeepLearningでは、以下の図のようにデータの形を欲しい形に変形していきます。
下記図では幅、高さが30ピクセルの画像を例にしています。
幅高さと奥行きが変化する過程にフィルタ処理が含まれています。
画像の分類ではCNN(Convolutional Neural Network)畳み込みニューラルネットワークと呼ばれるものを使います。
下記図もCNNのAIモデルを示したものです。

DeepLearningは画像などのデータを欲しいデータの形、結果に変換するものと考えて良いでしょう。
Deep Learningで使うライブラリ
Deep Learningで使われるライブラリは主に3種類あります。
pytorch、Tensorflow、kerasの3種類です。
| ライブラリ | 説明 |
|---|---|
| tensorflow | Google開発のライブラリで、DeepLearningが普及当時から使われてきたライブラリ |
| keras | tensorflowが後ろで動いていて、tensorflowをより使いやすい形にライブラリ化したもの |
| pytorch | Facebookによって開発されたライブラリで、numpyとかと同じように使え、柔軟に複雑なAIモデルを構築しやすいという特徴があります。 |
pytorchが人気
Google Trendsで比較するとpytorchがここ最近の人気ライブラリなのがわかると思います。
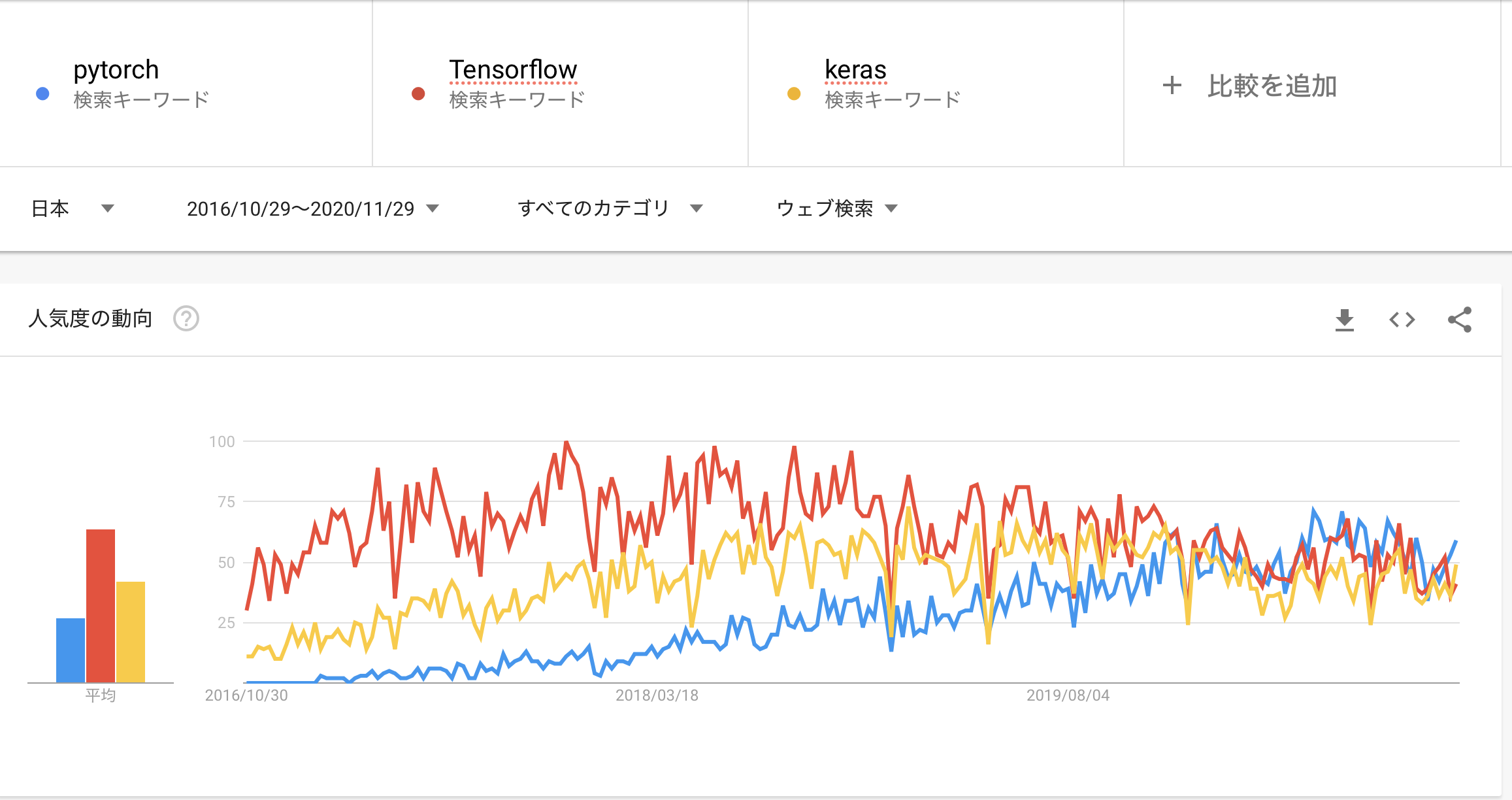
pytorchは普段のプログラム開発と似ていますが、tensorflowはAIモデルを先に設計してから動かすという「Define And Run」という方法を採用しているので、最初はとっつきにくいと思いますが、tensorflowとkerasのコードも多いので、両方習得しておくと良いでしょう。
pytorchで画像に写っているものを検出してみる
pytorchが人気ですし、わかりやすいので、pytorchを使っていきます。
インストール
下記よりインストールしてください。

「Your OS」からOSを選んで、「Package」はpipを選んでください。
GPUを使う方は、対象のCUDAのバージョンを、CPUの方はNONEを選択すると、コマンドが表示されますので、それを使ってインストールしてください。

VGG16というAIモデルを使って実行する
VGG16というAIモデルを使って、下記画像に何が写っているかAIに判定させてみましょう。

当然、人が見れば、ライオンですが、機械が簡単に人と同じようにライオンと判定してくれます。
早速コードを書いてみましょう。
といっても、下記のリンクをそのまま参照していきます。
ライブラリ読み込み
画像読み込みにはOpenCVでなく、PILというライブラリを使い、配列データを使いたいのでnumpyを読み込んでいます。
torchとなっているのはpytorch関連です。
|
1 2 3 4 5 |
import numpy as np import json from PIL import Image import torch from torchvision import transforms |
モデル読み込み
AI構造にはいろいろありますが、2014年からシンプルでよく使われているVGG16を使っていきます。
|
1 2 3 |
# 学習済みのVGG16のモデルを読み込み model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg16', pretrained=True) model.eval() |
コンマ数%でも精度をあげたい場合、VGG16以外にもいろいろなAIがあるので、試してみると良いでしょう。
学習に使われたデータはImageNetというところのデータを使っており、1000種類に分類してくれます。
transformsメソッドで正規化してtensor型にデータを変換する
画像データは読み込んだままでは使わず、画像のサイズを変換、0-255の値を正規化、Tensor型に変換をします。
こういったものだと、おまじないようにコードを実行しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 対象画像 filename = 'lion.jpg' # 読み込み画像をリサイズやtensorなどの型に変換 input_image = Image.open(filename) preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) |
最後のinput_batchが変換後のデータです。
GPU使うか判断
GPUが使える場合は、GPUを使えるようにします。
|
1 2 3 4 |
# GPU使える場合はGPUを使う if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda') |
GPUがあるけどあえて、CPUを使いたい場合は、’cuda’を’cpu’とします。
AIの判定
ここまでくれば、ライオンの画像をAIで判定できます。
modelにライオンの画像が変換されたinput_batchを入れて、結果をoutputに受け取ります。
outputはsoftmaxというを活性化関数を使うことで、どの分類かを出力します。
|
1 2 3 4 5 |
# AIの判定 with torch.no_grad(): output = model(input_batch) output = torch.nn.functional.softmax(output[0], dim=0) print(output.shape) |
学習済みのVGG16でが1000個に分類できるので、outputは1000個の配列となります。
結果を確認
outputは1000個の分類種類のうちどれに値が一番大きいものを参照するば、どの分類に該当するかの番号を取得できます。
argmaxメソッドで1000個の配列のうちどれが一番大きいか取得します。
|
1 2 3 4 |
# 出力結果から1000種類のうちどれかを数値で取得 output = output.to('cpu').detach().numpy().copy() ind = np.argmax(output) print(ind) |
291となりました。この画像は291番目の何かだということですね。
その番号から名称を取得するために、下記から名称を取得します。

jsonのファイルをダウンロードしたら、下記を実行します。
|
1 2 3 4 |
# 1000種類の分類結果からAIが判定したものを表示 class_index = json.load(open('imagenet_class_index.json', 'r')) labels = {int(key):value for (key, value) in class_index.items()} print(labels[ind]) |
|
1 |
['n02129165', 'lion'] |
lion(ライオン)とうまく判定されています。
従来の画像処理ではすべての特徴をデータ化しなければならない
従来の画像処理では、ライオンを検知する場合には、色や尻尾、毛の長さなど人が画像処理でデータ化してそのデータから分類をすることになります。
しかし、1000種類も分類するデータに作れませんし、そもそも、画像処理で尻尾の有無を検出するだけでも大変です。
DeepLearningでは、そう言ったことは一切気にせず、VGG16などのAI構造に学習させるだけで、分類することが可能です。
まとめ
DeepLearningのライブラリのうち、pytorchを実際に使ってみました。
どうでしょう?30行足らずのコードで、AIが動かせましたね。
初めて、pytorchを使う方はデータの読み込み、変換やAIを動かすところなど分かりにくいところがあったかもしれません。
最初は動かすことが大事ですので、わからないところは順番に理解を深めていきましょう。