

横浜国立大学理工学部建築都市環境系学科卒
一級鉄筋技能士
唎酒師
狂人のごとく特定の分野、中小企業を理解し、国の補助金を獲得します。最近は中小企業のM&Aにも挑戦中
日々の業務でExcelを使っていると、気づかないうちに大量のテーブルデータが蓄積していきます。
売上、在庫、顧客対応、点検記録――どれもビジネスの現場で蓄積され続ける貴重な情報資産です。
グラフ化による可視化や関数による分析で工夫している方も多いと思いますが、「もっと賢くデータを活かせないか」「もっと工夫して自動化できないか」と感じたことはありませんか?
そうした課題感を抱えている方にこそ、クラウドを用いた機械学習にチャレンジしてほしいのです。
グラフにするだけで終わっていませんか?
予測や分類に活かせそうなデータが眠っていませんか?
日々向上心を持って仕事をされている方はぜひ、AWS(Amazon Web Services)の活用にチャレンジしてみてください。
株式会社momonkiでは、UDEMYで実践的なExcelデータの前処理・可視化方法の講座を公開しています!Excelの基礎から確認したいよーという方はこちらの講座をどうぞ!「Excelデータ活用入門 データの前処理・可視化」はこちらから!


目次
Excelデータの前処理・可視化と機械学習の違い
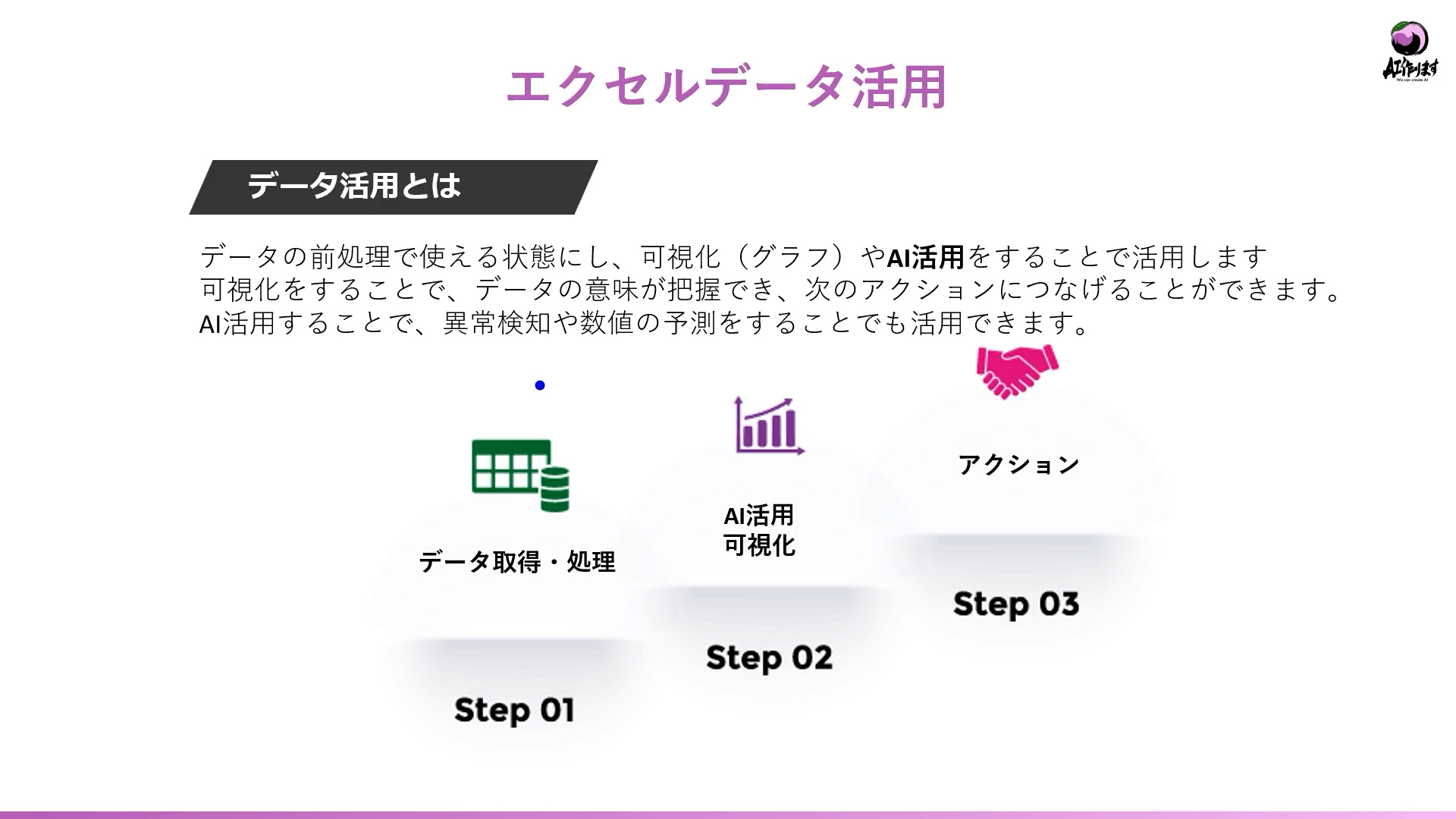
Excelを使ったデータ活用と、機械学習を用いた分析には明確な違いがあります。
どちらも「データから価値を引き出す」という目的は共通していますが、そのアプローチや処理能力、実現できる範囲には大きな差があります。
大量のデータを取り扱う時など、人間ではパターンを見つけられない時は機械学習が必要になる
Excelでは、関数やグラフ、ピボットテーブルなどを用いてデータを整理・可視化できます。
これにより、「売上の推移」「在庫の変動」「顧客の属性分布」などを視覚的に捉えることが可能になります。
たとえば、月別の売上データをグラフ化することで、売上が季節によってどう変動するかを一目で確認できるようになります。
しかしながら、可視化はあくまで“過去”を見て判断する手段です。
「なぜ売上が下がったのか」を理解するには役立っても、「次にどうなるか」や「どうすれば改善できるか」といった未来への対応は、担当者の経験や勘に依存してしまいがちです。
ここで機械学習の出番です。
機械学習では、人間の直感や経験では見つけにくいような複雑なパターンを、過去のデータから自動的に学習させることができます。
たとえば、以下のようなことが可能になります。
|
1 2 3 4 5 |
・顧客の属性や購買履歴から、将来的な離脱リスクを予測 ・過去の生産状況から、機械の故障や不良品の発生を事前に察知 ・売上や気温、販促履歴など複数の要因をもとに、来月の売上を自動予測 |
機械学習によって将来の予測ができれば、人の経験・勘に依存しない自動化が可能になる

機械学習の最大の強みは、複数の要因が絡み合うような多次元データの中から、統計的に意味のあるルールを見つけてくれる点にあります。
たとえば、「売上は気温が高く、かつ前週に広告を打っているときに伸びやすい」など、人の感覚では直感的につかみにくい傾向も、機械は正確に検出してくれます。
また、こうしたモデルは学習して終わりではありません。
新しいデータが入ったときに、即座に予測を返してくれる仕組みがあるため、「その都度人が判断する」体制から脱却し、自動化が可能になるのです。
機械学習の出番は、大量のデータから自分にはわからないパターンを見つける時
機械学習の流れ
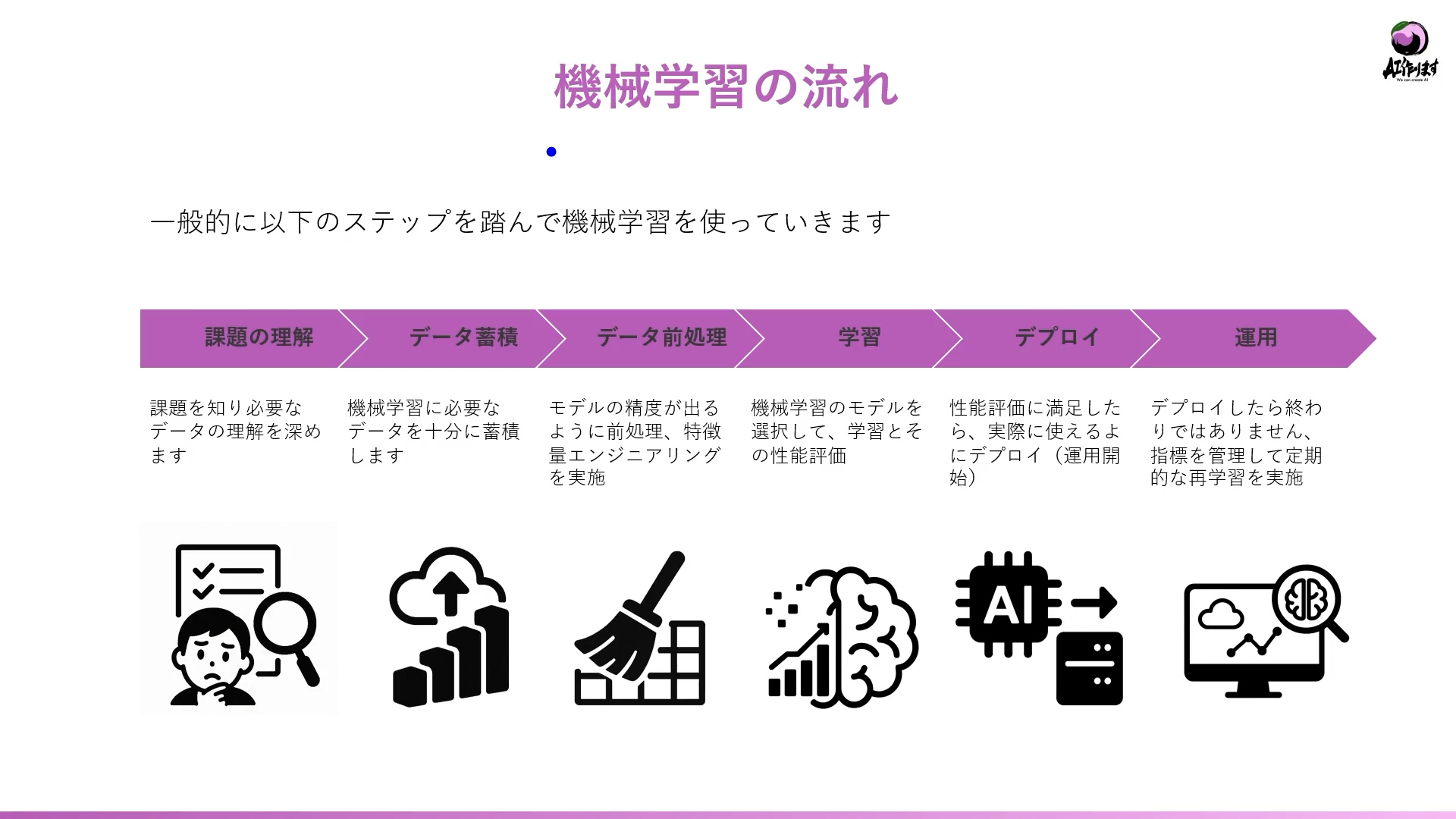
機械学習を業務に取り入れる際には、以下のような段階を踏んで進めていきます。
課題の理解
まずは「どの業務課題を解決したいのか」を明確にすることがスタート地点です。
たとえば、
|
1 2 3 4 5 |
・顧客の購買傾向を分析し、再購入を促したい ・品質異常を検知し、不良率を下げたい ・業務のどこに時間がかかっているかを把握したい |
といった目的を設定します。
目的が曖昧だと、分析の方向性もぶれてしまいます。最終的に得たい「行動につながる示唆」を明確にしましょう。
データの蓄積
目的が定まったら、その分析に必要なデータを収集・整理します。
Excelなどに既に蓄積されているデータを見直し、「何が使えるか」「足りない情報は何か」を確認します。
基本的には、ある程度のデータ量(最低でも数百件〜数千件)があることが望ましく、データ量が多いほど機械学習の精度は高くなります。
データの前処理
Excelで作成したデータは、そのまま機械学習に使えるとは限りません。
不要な列を除外したり、カテゴリ変数を数値に変換したり、欠損値を補完したりといった処理が必要になります。
この前処理の工程は非常に重要で、分析結果の精度を大きく左右します。
ここでは「特徴量エンジニアリング」と呼ばれる技術も用いられ、モデルの性能向上につながる新たな指標を人工的に作り出すこともあります。
学習
前処理されたデータをもとに、実際に機械学習モデルを構築します。
分類(例:スパムメールか否か)や回帰(例:価格の予測)など、目的に応じたアルゴリズムを選び、AIに「学習」させます。
ここでは「交差検証」や「正解率」「精度」などの指標を用いて、モデルの良し悪しを評価します。
十分な精度が出ていなければ、前処理に戻って調整を行うこともあります。
デプロイ(モデルの実用化)
学習されたモデルが一定の精度に達したら、実際に業務で使えるように「デプロイ(展開)」します。
デプロイされたモデルは、業務アプリやシステムと連携して、リアルタイムで予測や判断を返す仕組みになります。
たとえば、ECサイトの画面に「この商品もおすすめです」と表示されたり、製造ラインでセンサー情報をもとに「この製品は異常かもしれない」とアラートを出したりするのが、この段階です。
運用
モデルは一度作って終わりではありません。
時間の経過とともにデータの傾向が変化すれば、モデルの精度は徐々に低下していきます。
そこで、新しいデータを使って再学習し、モデルをアップデートする必要があります。これが「機械学習の運用」フェーズです。
継続的に精度を監視しながら、業務にしっかりと根付かせていくことが、データ活用の成否を左右します。
AWSを使ってみよう!
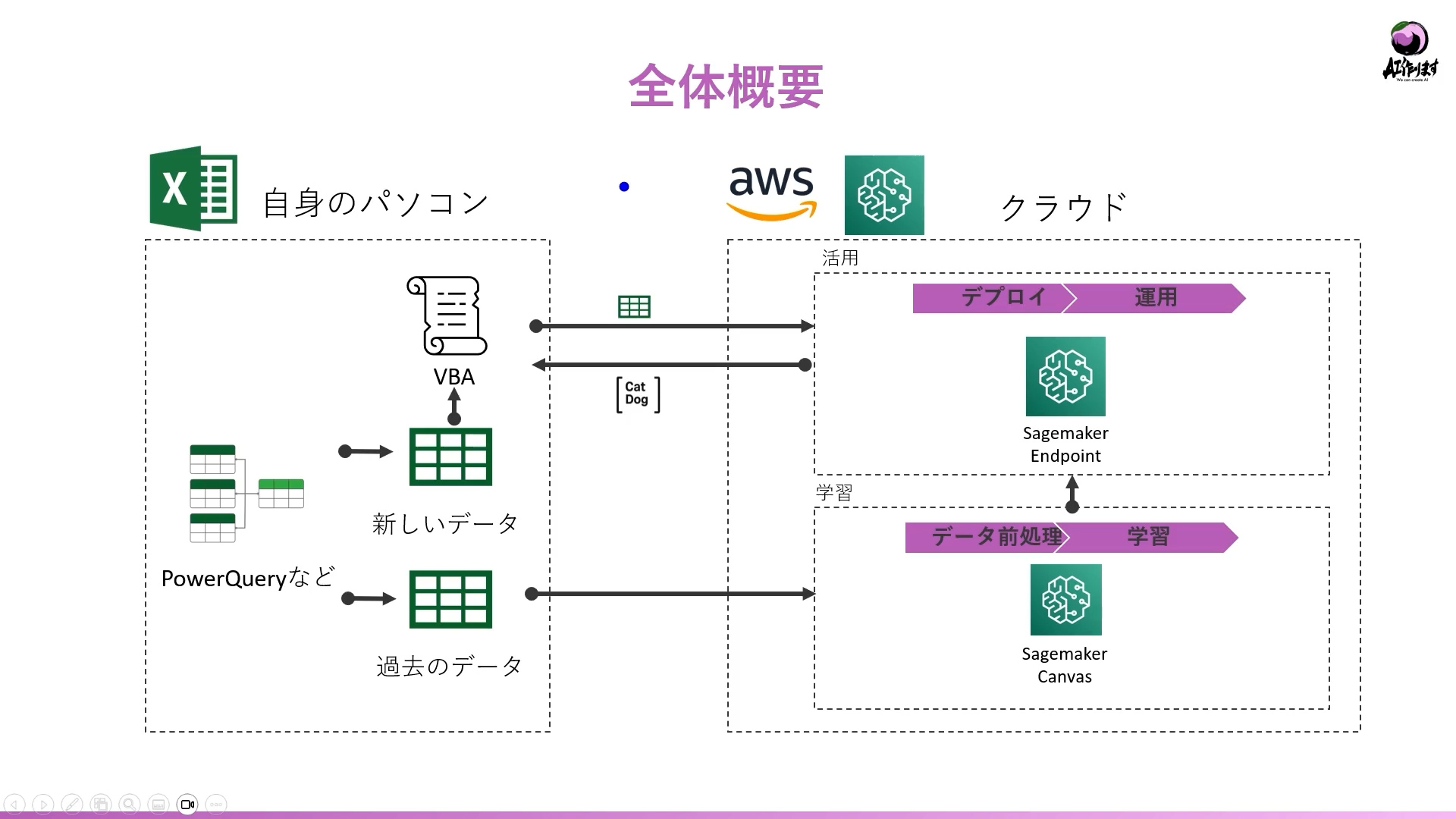
ここまで聞いて、「でも、自分はエンジニアじゃないから難しい」と感じた方も多いかもしれません。
しかし、心配は不要です。
現在はプログラミング不要で機械学習を活用できるツールが次々と登場しており、その代表格がAmazon SageMaker Canvasです。
SageMaker Canvas
SageMaker Canvasは、AWSが提供するノーコードの機械学習ツールで、主に以下のような特徴があります。
|
1 2 3 4 5 6 7 |
・Excelファイルをそのまま読み込み可能 ・ドラッグ&ドロップのGUIで前処理、モデル作成ができる ・予測結果は表形式で返され、Excel感覚で確認可能 ・デプロイもボタン一つで可能、リアルタイム予測も実現可能 |
たとえば、数千件の売上データをCanvasにアップロードし、商品カテゴリや季節、販促有無などの列を活用することで、翌月の売上を予測するモデルを作ることができます。
そして、このモデルは業務で「使える状態」にまで持っていけます。たとえば、VBAでExcelからAPI(エンドポイント)に接続すれば、新しい商品情報を入力するだけで、売上予測がリアルタイムに返される仕組みを簡単に構築できます。
さらに、AWSのメリットはスモールスタートが可能な点です。
必要な時に、必要な分だけの課金で利用できるため、初期費用がかかりすぎるという心配もありません。
小さなプロジェクトから始めて、徐々にスケールアップしていくことができます。
Excelデータの基本的な活用方法はこちらから!
次の記事では、具体的にAWSの使用方法についてご紹介していきます!!
株式会社momonkiでは、UDEMYで実践的なExcelデータの前処理・可視化方法の講座を公開しています!Excelの基礎から確認したいよーという方はこちらの講座をどうぞ!「Excelデータ活用入門 データの前処理・可視化」はこちらから!